日本正積極佈局日語大型語言模型(Large Language Model, LLM)的發展。近年日本政府和企業都高度重視AI技術,投入研發資源希望在此領域取得突破性進展。根據總務省2024年版情報通信白皮書,目前日本民眾使用生成式AI比例有9%,與歐美相對較低;但對未來使用持正面態度,在製作及翻譯文件、查詢資料、利用AI諮詢健康及疾病資訊等潛在需求預估達7成,看好日本AI發展前景。
為了掌握日本市場需求,全球領先的AI公司OpenAI宣佈在東京設立亞洲第一個辦公據點,並推出專為日語使用者設計的GPT-4 Turbo模型。這款模型的運算能力是GPT-4的4倍,處理日語內容的速度更是3倍,可見OpenAI對日本市場的重視程度。
日本國內企業和研究機構也積極發展自有大型語言模型。日本電信電話公司(NTT)開發以日文為主的輕量級模型tsuzumi,定位為擁有專業知識的小型語言模型,已開始應用在金融、醫療等領域;Line(Line Yahoo)則推出Japanese-large-lm模型,使用LINE自己的大型日語網頁來訓練模型,為日語的開源軟體。此外,日本廣告公司Cyber Agent發行了Cyber Agent LM2-7B模型,另有發行聊天版本的CyberAgentLM2-7B-Chat,可以一次處理5萬字的日語文章。
日本國立研究開發法人情報通信研究機構(NICT)與KDDI株式會社開始共同開發大型語言模型,NICT蒐集600億件以上的網頁資料,搭配KDDI開發的幻覺抑制技術及多模型AI技術,致力提高執行系統的信賴性。日本軟體公司Stability AI Japan推出Japanese Stable LM Alpha大型語言模型,其學習資料涵蓋日文和英文,為研究目的而創建的模型,發表後僅供研究使用。
日本企業和研究機構正全面著力大型語言模型的發展。隨著OpenAI、日本本土企業及國家研究機構的努力,未來日本在大型語言模型的發展精彩可期
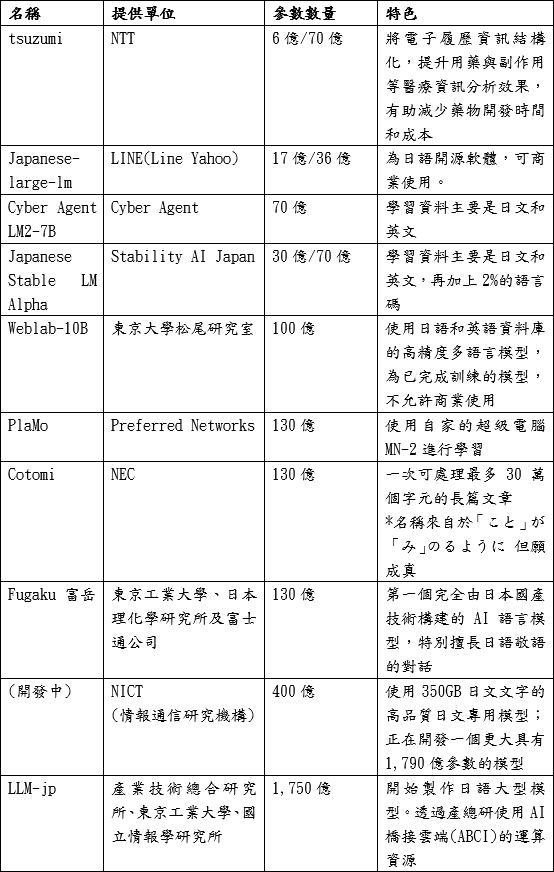
圖:日本主要LLM
資料來源:
- 期待高まる国産生成AI(前編)──AIの歴史的変遷と大規模言語モデルの動向NTT情報通信總合研究所
- 令和6年版情報通信白書(概要)
- OpenAI Japan 始動
- NTT版LLM tsuzumiの概要
- 36億パラメータの日本語言語モデルを公開しました
- 独自の日本語LLM(大規模言語モデル)のバージョン2を一般公開 ―32,000トークン対応の商用利用可能なチャットモデルを提供―
- 日本語言語モデル「Japanese StableLM Alpha」をリリースしました
- NICTとKDDIが大規模言語モデルに関する共同研究を開始